
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- neural networks #linear #nonlinear #perceptrons
- 네이버
- Optimization
- confusion matrix
- objectdetection
- map
- precision
- 부트캠프
- deep learning #machine learning #history
- 1x1 convolution
- AI tech
- FPS
- evaluation
- momentum #adagrad #adam #early stopping #data augmentation #dropout #label smoothing #batch normalization
- generalization #overfitting # bootstrapping #bagging #boosting #stochastic gradient desent #mini-batch gradient descent #batch gradient descent
- flops
- CNN #padding #stride #parameters
- 대학원생
- recall
- IOU
- 일상
Archives
- Today
- Total
공부 일기장
ILSVRC(modern models) 본문
ILSVRC 에서 해마다 우수한 성능을 보였던 모델들의 핵심만 리뷰
모델이 발전해가면서 네트워크의 depth는 점점 깊어지면서 parameters는 점점 줄어든다.
AlexNet
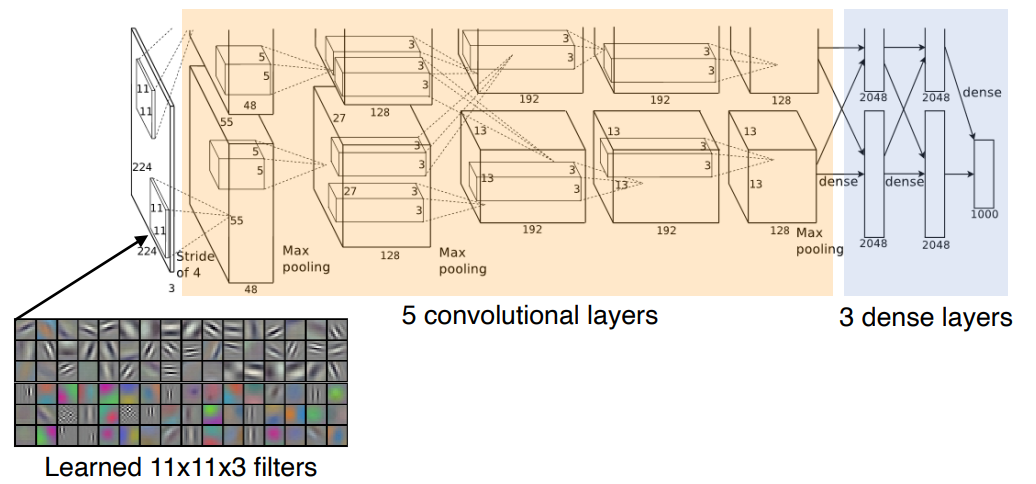
- 11x11 Input
- 파라미터 숫자 관점에서는 좋지 않은 선택
- 해당 필터는 receptive field는 넓어질 수 있지만 상대적으로 더 많은 파라미터가 필요
- 8-layers
- 5 conv + 3 dense
Key ideas
- ReLU(Rectified Linear Unit) activation
- overcom the vanishing gradient problem
- good generalization
- GPI implementations(2 GPUs)
- Data augmentation
- Dropout
VGGNet
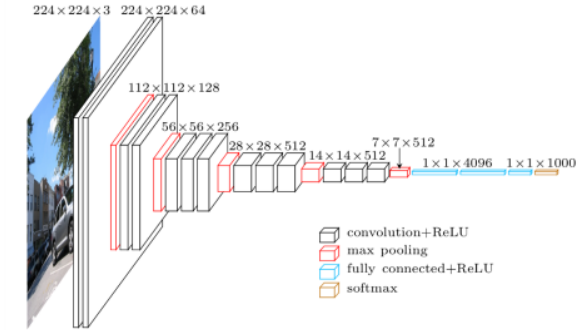
- 3 x 3 convolution filters의 반복을 통해서 depth를 증가
- 1 x 1 convolution을 FC layer로 사용
- Dropout
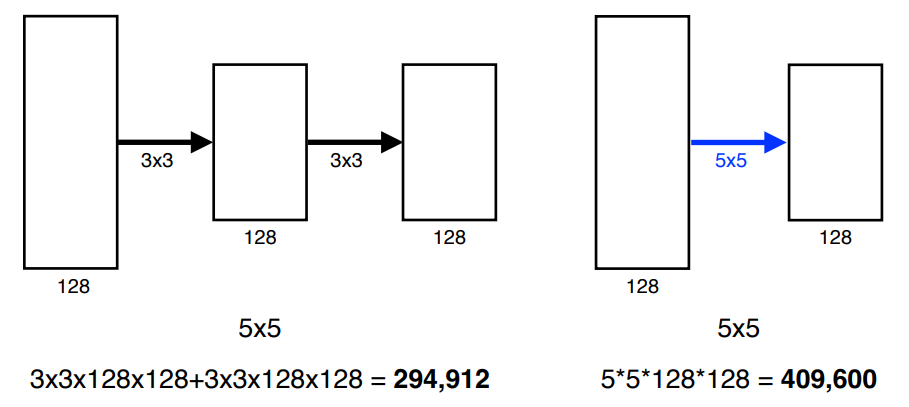
Why 3 x 3 convolution?
- same receptive field
- low parameters
GoogleNet
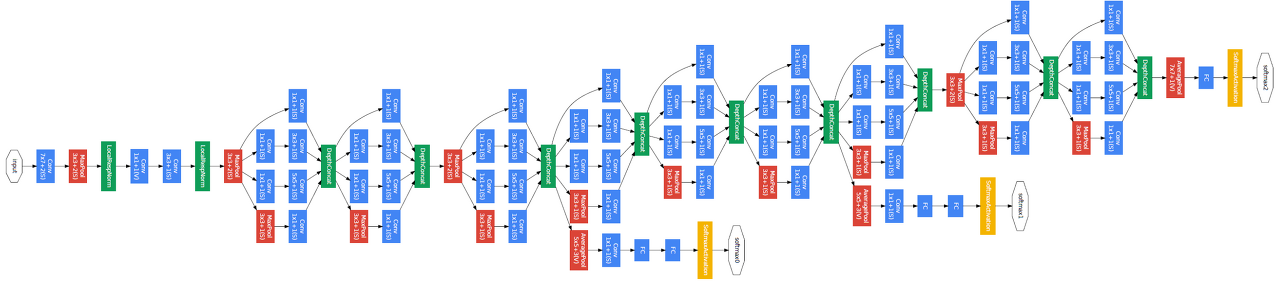
- Inception Block
- 하나의 입력에 대해서 여러개의 receptive field를 가지고, 여러개의 instance들을 concat하는 효과
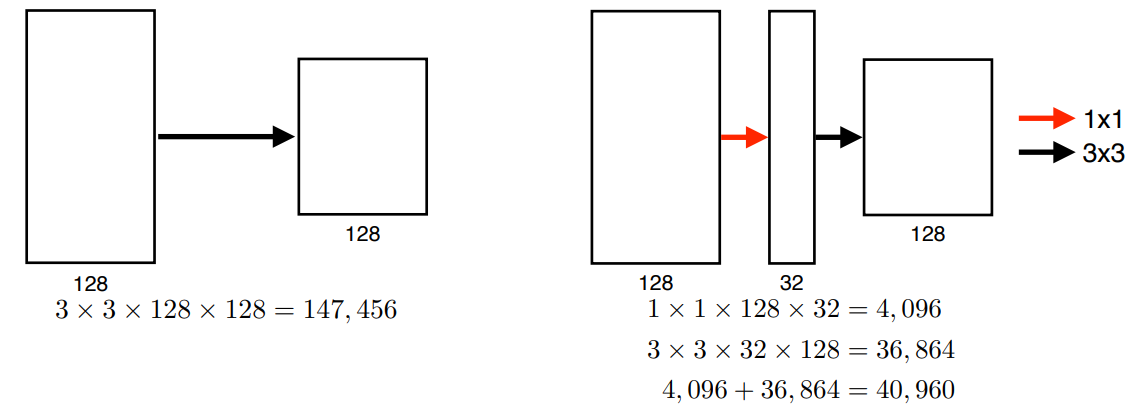
- 1 x 1 conv를 끼워넣어서 파라미터의 수를 줄인다
- channel-wise reduce
ResNet
네트워크가 커짐에 따라서 학습 자체가 잘 안되는 현상을 해결
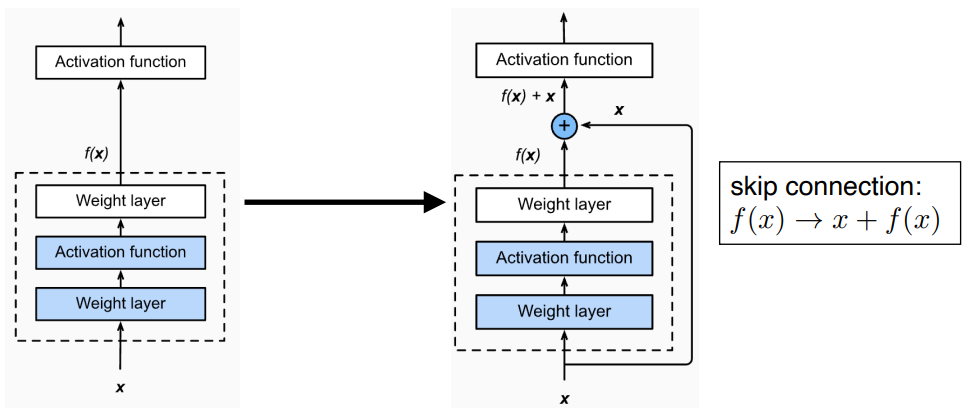
- skip connection을 통해서 identity mapping
DenseNet
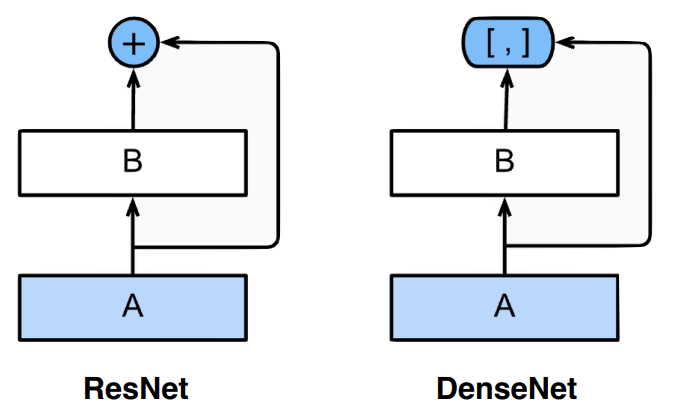
- addition 대신에 concatnate로 구조를 변경
'네이버 부스트 캠프 > DL basic' 카테고리의 다른 글
| Convolutional Neural Networks (0) | 2023.02.27 |
|---|---|
| Optimization (0) | 2023.02.27 |
| Neural Networks & Multi-Layer Perceptron (0) | 2023.02.27 |
| Historical Review (0) | 2023.02.27 |
'네이버 부스트 캠프/DL basic' Related Articles
more




Comments