
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- generalization #overfitting # bootstrapping #bagging #boosting #stochastic gradient desent #mini-batch gradient descent #batch gradient descent
- 일상
- CNN #padding #stride #parameters
- 1x1 convolution
- 부트캠프
- AI tech
- momentum #adagrad #adam #early stopping #data augmentation #dropout #label smoothing #batch normalization
- confusion matrix
- precision
- IOU
- flops
- 네이버
- recall
- deep learning #machine learning #history
- FPS
- evaluation
- map
- Optimization
- neural networks #linear #nonlinear #perceptrons
- objectdetection
- 대학원생
Archives
- Today
- Total
공부 일기장
Optimization 본문
용어들에 대해서 확실하게 알고 넘어가보자
[관련 용어]
- Generalization
- 일반화 성능? - generalization gap이 작다

- Under-fitting vs Over-fitting

- Cross-validation

- Bias-variance trade-off
- variance : 비슷한 입력들을 넣었을 때 출력 또한 일관적인지
- bias : 입력들이 true target의 근처에 모여있는지
- cost = bias + variance + noise
- trade-off 관계

- Bootstrapping
- 여러 sampling data를 통해 여러 모델을 만드는 것
- Bagging and boosting
- Bagging
- 학습데이터를 여러개를 만들어서(bootstrapping) 여러모델을 학습시키고 결과값을 평균
- N개의 모델 모두 돌려보고 결과값을 계산하는게(앙상블) 좋은 성능을 가지는 경우가 많다.
- Boosting
- 여러개의 모델을 하나로 합쳐서 잘 못맞추는 데이터를 학습시켜서 잘 맞추도록
- weak learner를 모아서 하나의 strong learner로 구축
- Bagging
[Gradient Descent 종류]
Gradient Descent
First-order iterative optimization algorithm for finding a local minimum of a differentiable function
- Stochastic gradient descent
- single sample로부터 gradient를 계산, 업데이트하는 방식
- Mini-batch gradient descent : 대부분의 딥러닝에 활용되는 방식
- data의 subset로부터 gradient를 계산, 업데이트하는 방식
- Batch gradient descent
- 전체 data로 부터 gradient를 계산, 업데이트하는 방식
우리는 Batch 기반 최적화를 할때, Batch-size matters를 고려할 줄 알아야 한다.

[다양한 최적화 기법]
- (Stochastic) Gradient descent
- learning rate 잡는게 너무 어려움

- Momentum
- 한번 흘러간 gradient의 흐름을 다음 번 계산할 때 흘려줘서 같이 활용
- 하지만 관성 때문에 local minimum에 fit이 안되는 문제가 있음

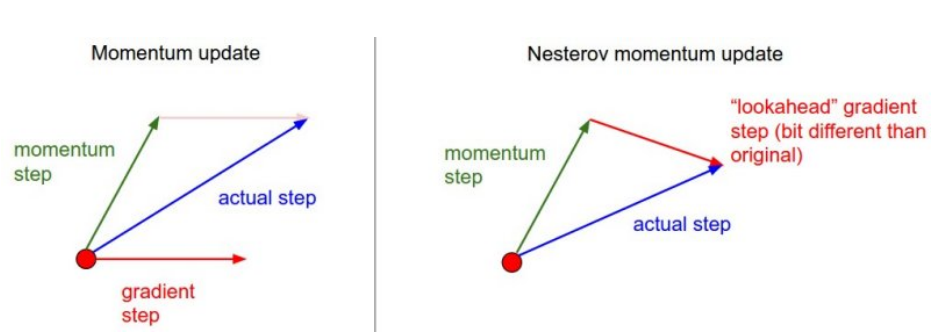
- Nesterov Accelerate
- momentum의 성질을 활용하지만 다음번 gradient는 momentum과는 달리 조금 이동해서 gradient를 계산
- local minimum에 조금 더 빨리 fit하게 됨

- Adagrad
- neural network의 파라미터가 얼마나 변해왔는지, 얼마나 변하지 않았는지를 보게 됨
- 많이 변한 파라미터들에 대해서는 적게, 적게 변한 파라미터들에 대해서는 많이 변하도록
- 그래서 지금까지 변한 파라미들에 대한 정보를 저장(sum of gradient squares)
- 하지만 뒤로 가면 갈수록 파라미터들에 대한 정보는 커지고 분모가 커지면서 변화값이 0에 가까워지고 학습이 점점 멈춰지는 현상이 생김

- Adadelta
- Gt가 커지는것을 최대한 막아주는 함수를 추가
- no learning rate
- RMSprop
- Adam
- effectively combines momentum with adaptive learning rate approach

[Regularization 기법]
generalization을 잘되도록 하는 것
학습을 방해함으로써 학습데이터에만 잘 동작하는 것이 아닌 test data에도 잘 작동하도록 하는 것
- Early Stopping
- loss를 보고 어느 시점부터 커지기 시작한다면 해당 시점부터 멈추도록 하는 것
- Parameter norm penalty
- network의 파라미터 숫자의 크기를 작게 하자
- function space가 최대한 부드러운 함수로 만들도 그럴수록 generalization performance가 좋다
- Data augmentation
- 데이터가 많아지면 많아질수록 딥러닝 모델의 효과가 좋은데 사실 데이터는 한정적
- 그래서 데이터를 증강하는 것이 필요
- Noise robustness

- Label smoothing
- 각 라벨의 boundary를 섞어주는 것
- mixup - 성능이 생각보다 엄청 많이 상승함
- cutmix
- cutout

- Dropout
- neural network의 weight를 0으로 만들어 버리는 것
- 각각의 뉴런들이 조금 더 robust한 feature를 가지도록 함
- Batch normalization
- 내가 적용하고자 하는 layer의 값들을 normalization 해주는 것
- 이를 활용하게 되면 성능이 많이 올라가게 된다.
'네이버 부스트 캠프 > DL basic' 카테고리의 다른 글
| ILSVRC(modern models) (0) | 2023.03.06 |
|---|---|
| Convolutional Neural Networks (0) | 2023.02.27 |
| Neural Networks & Multi-Layer Perceptron (0) | 2023.02.27 |
| Historical Review (0) | 2023.02.27 |
'네이버 부스트 캠프/DL basic' Related Articles
more




Comments